ИИ-Ассистент в M42: Как Ускорить Поиск Метрик в 2025 🚀
- m42copilot — это сервис, который позволяет пользователям M42 (BI-инструмент Авито) строить графики и находить нужные метрики, используя обычный язык. Забудь про ручной перебор! По сути, это переводчик между твоим бизнес-вопросом и сложной структурой данных, где больше 16 000 метрик и 120+ разрезов.
Что такое M42 и почему ему нужен ИИ-помощник?
Представь, что у тебя есть гигантская библиотека, где каждая книга — это ценнейшая бизнес-метрика. В нашей системе M42 таких "книг" — свыше 16 000. Это серьезный BI-инструмент, созданный, чтобы продакт-менеджеры и бизнес-пользователи могли находить инсайты, даже не зная SQL или Python.
Вместо того чтобы писать код, они комбинируют готовые метрики и фильтры. Но когда метрик так много, поиск нужной и правильная настройка фильтров превращается в настоящий квест.
Вот основные факты о M42:
- Масштаб: Более 16 000 метрик и 120+ разрезов.
- Кто пользуется: Бизнес-аналитики (62% активны) и продакт-менеджеры.
- Боль: Сложность поиска и настройки из-за этого масштаба.
Семантический слой: Фундамент для Понимания ИИ
Прежде чем мы вообще начали "прикручивать" ИИ, мы заложили крепкий фундамент. M42 работает поверх семантического слоя. Это наш единый глоссарий для всего, что происходит в компании.
- Как это работает? Каждая метрика имеет стандартизированные поля: имя, описание, методология. Разрезы (фильтры) тоже описаны максимально четко. Почему это так критично? Единый, стандартизированный формат — это то, что позволяет LLM (большим языковым моделям) понимать наши данные, а не просто "галлюцинировать" ответы.

В контексте этого слоя, ИИ-ассистент должен сопоставить запрос типа "покажи DAU" с внутренним, стандартизированным именем метрики (например, core_metrics.daily_active_users). Ниже — упрощенный пример на Python, который показывает, как имитировать поиск самой релевантной метрики, используя наш словарь семантического слоя.
__PROTECTED_1__
Этот код просто имитирует, как LLM получает запрос ("дневная активность пользователей") и ищет совпадения в SEMANTIC_LAYER. Честно говоря, в реальной системе мы используем векторизацию, а не простой поиск по подстроке.
Как ИИ-Ассистент Преобразует Текстовый Запрос в График? ⚡
Главная задача нашего ИИ-ассистента — превратить человеческую речь в команды, понятные M42.
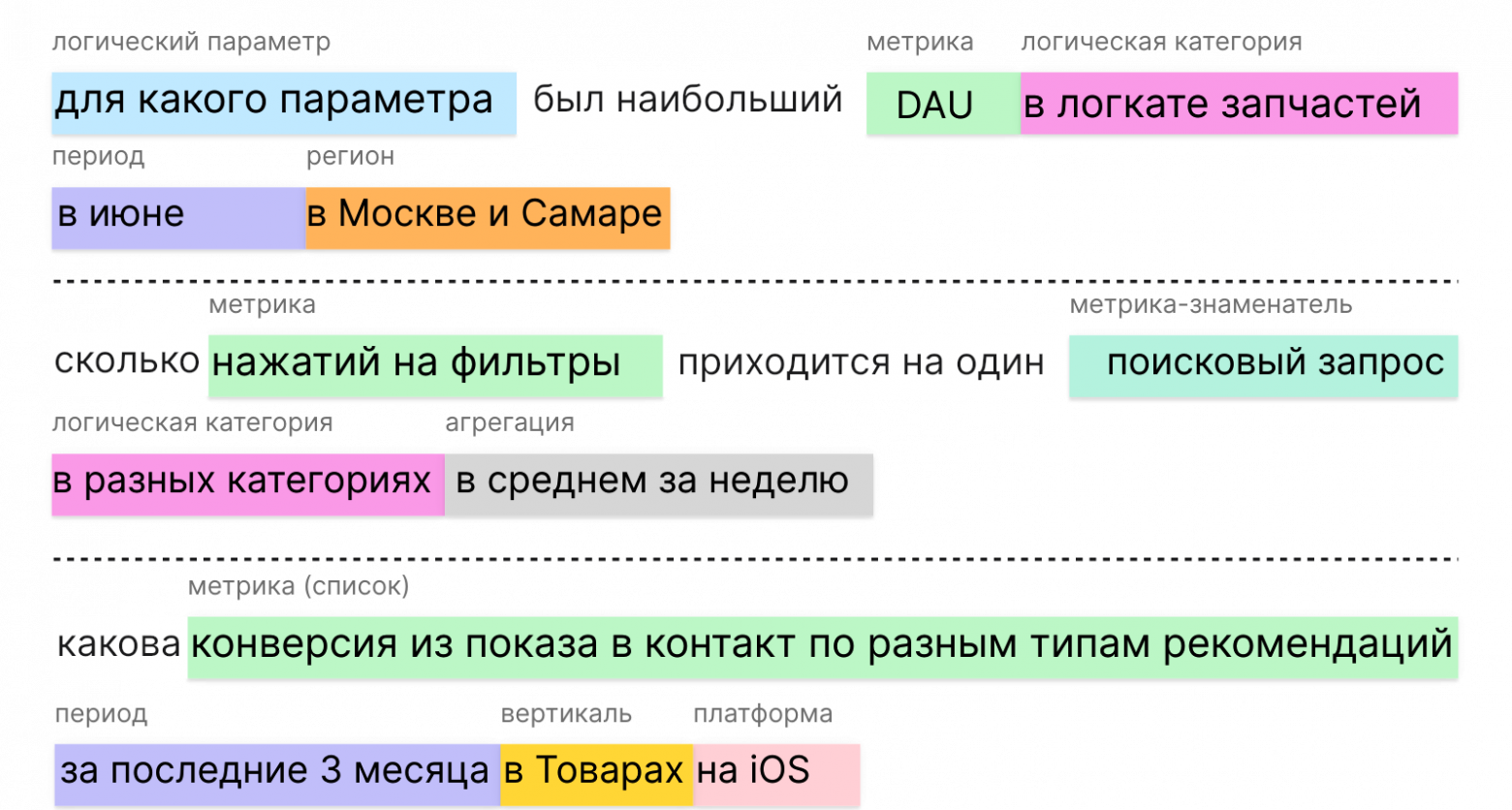
Вот пример: пользователь пишет: "Покажи дау по Электронике в первом квартале 2025 в виде таблицы с процентом изменения к прошлой неделе" (см. IMAGE_3).
Ассистенту нужно сделать следующее:
1. Вычленить метрику (dau).
2. Определить разрезы (Электроника, Q1 2025).
3. Выбрать формат вывода (таблица, % изменения).
Это не просто сопоставление слов. Нужнo понимать сленг (дау, arpu) и неточные формулировки. По данным нашего пилотного тестирования, ручная трансформация таких запросов в точные SQL- или MQL-выражения занимала у аналитиков от 3 до 7 минут. Внедрение ИИ-ассистента сократило это время до менее чем 30 секунд в 85% случаев.
Архитектура: Микросервис и Связка LLM + RAG
Наш ассистент — это микросервис на Python. Его сердце — это взаимодействие с LLM через три ключевых механизма:
1. RAG (Retrieval-Augmented Generation): Мы ищем релевантный контекст в нашей базе метрик. Это нужно, чтобы LLM не пыталась выдумывать факты.
2. Few-shot примеры: Мы подбрасываем в промпт несколько готовых примеров вида "запрос -> правильный JSON-ответ".
3. Структурированный вывод (JSON): Мы требуем от модели возвращать ответ строго в формате JSON, используя только заранее заданные допустимые значения.
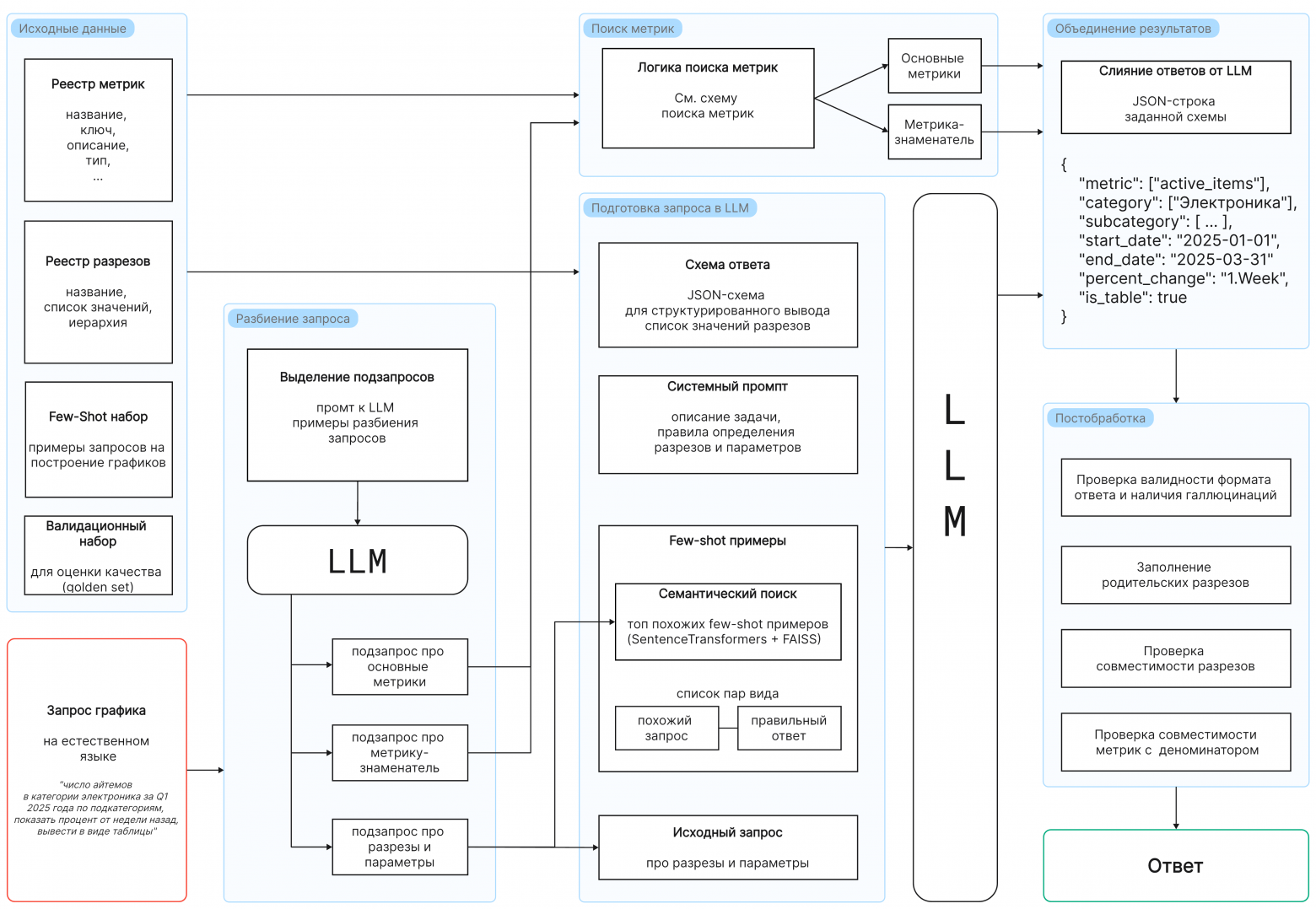
- Как обрабатывается запрос (коротко):
Шаг 1: Разделяем запрос на три части (основная метрика, знаменатель, прочие параметры). Это дает нам возможность искать метрики параллельно с разбором фильтров.
Шаг 2: Формируем промпт для LLM. Мы инструктируем модель вести себя как аналитик и даем ей четкую JSON-схему вывода.
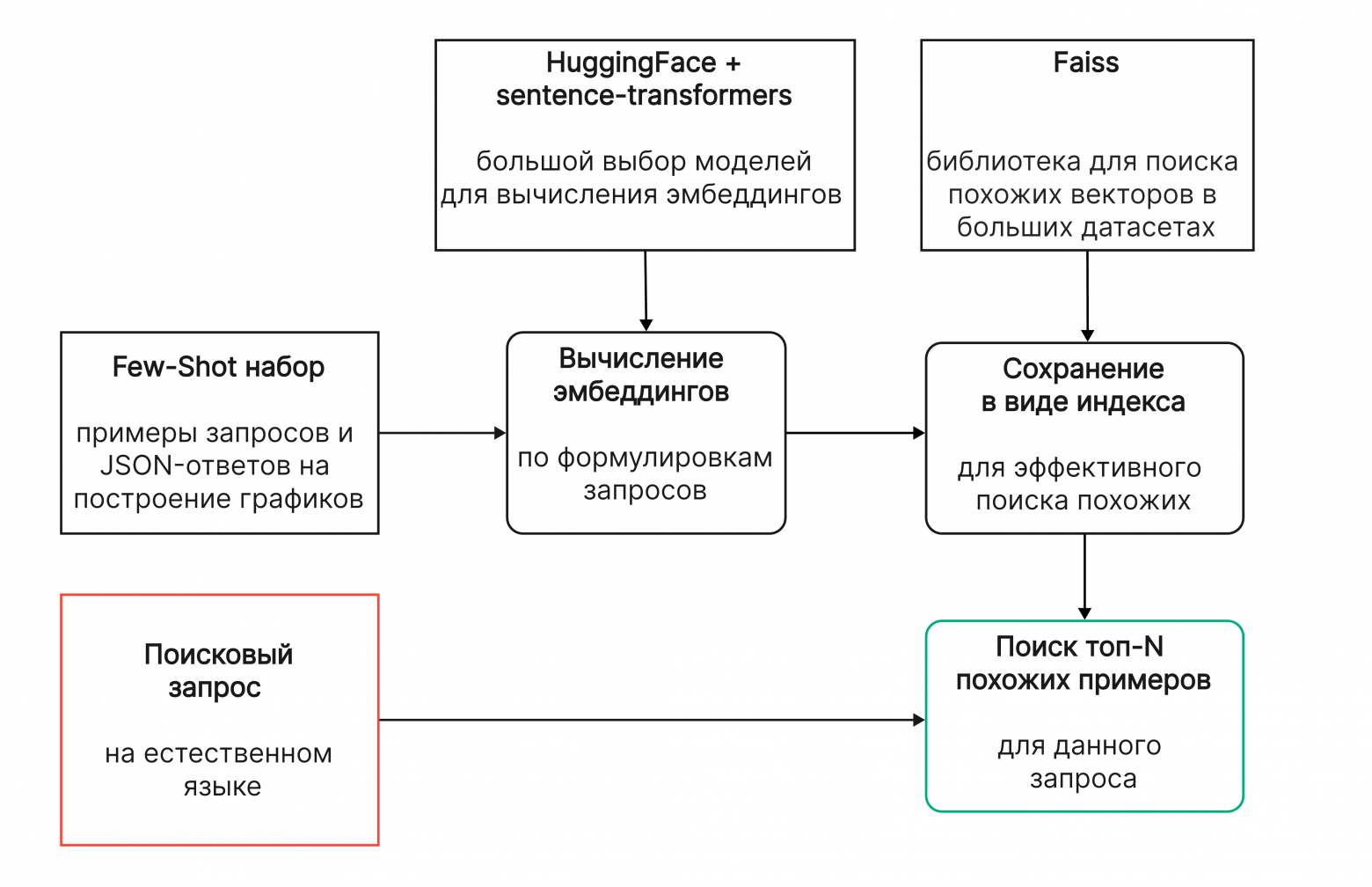
Шаг 3: Используем RAG для подбора лучших few-shot примеров. Мы кодируем запрос в эмбеддинги (например, через rubert-mini-frida) и ищем ближайших соседей в Faiss-индексе.
> Аналогия: Подумай, что ты учишь стажера готовить сложное блюдо. Проще дать ему рецепт (JSON-схему) и показать 5 идеальных примеров (few-shot), чем просто сказать: "Сделай вкусно".
Как Обеспечить Точный Поиск среди 16 000+ Элементов?
Поиск нужной метрики — это отдельная, непростая задача. Нельзя просто засунуть 16 000 названий в JSON-схему. Нам нужен надежный фильтр кандидатов, прежде чем мы обратимся к LLM.
- Вот наш многоуровневый подход к поиску кандидатов:
1. Семантический поиск: Классический RAG, но он работает только по названиям и описаниям всех метрик. Мы предварительно "чистим" описания от ненужного технического шума.
2. Нечеткий лексический поиск: Помогает, если пользователь помнит только часть слова (например, "событие 6552"). Здесь мы используем rapidfuzz.
3. Точный поиск: Для прямых попаданий или транслитерированных аббревиатур (например, "dau" -> "dau").
4. Топ популярных: Если ничего не найдено, даем модели самые популярные метрики.
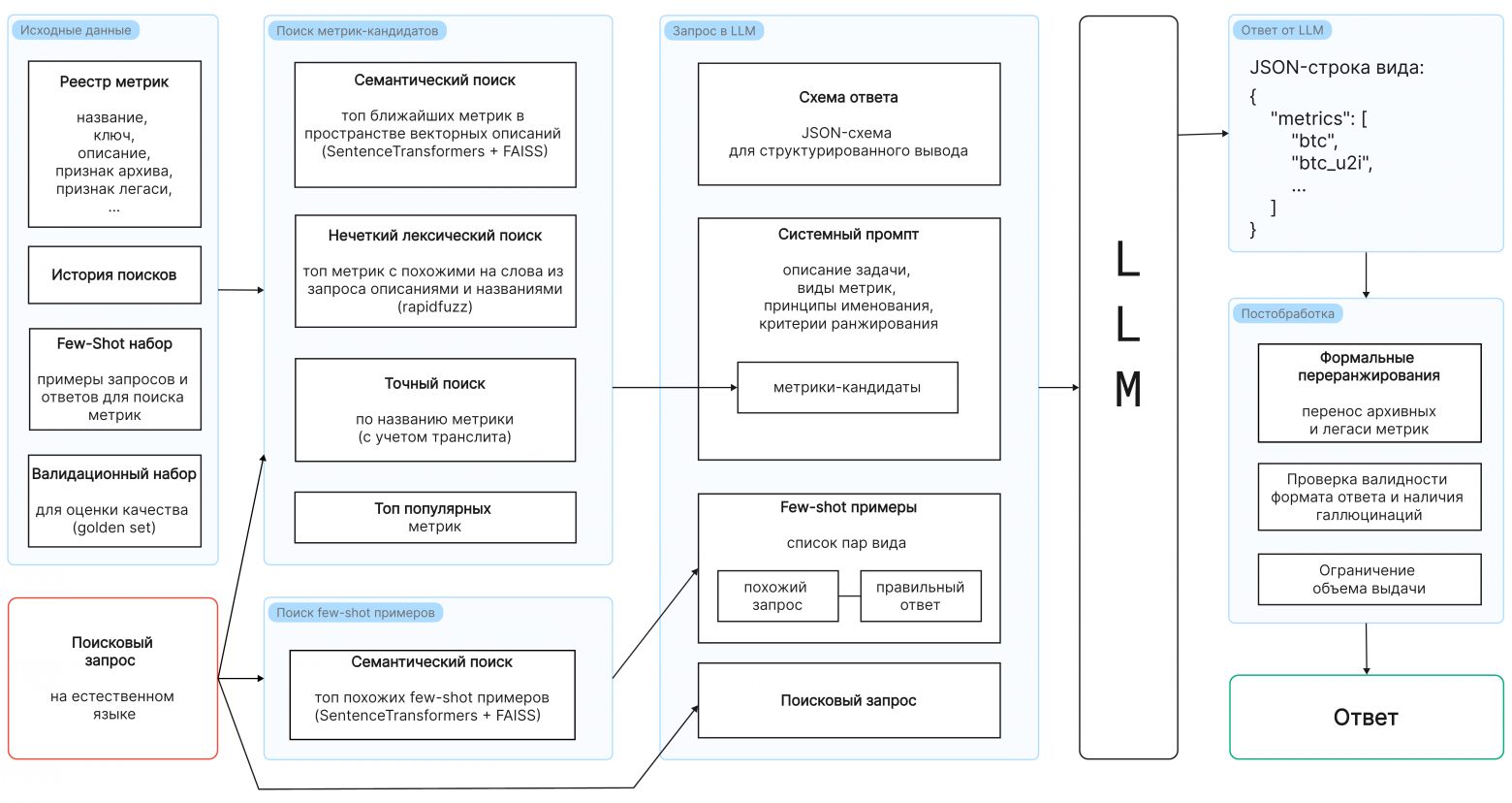
После того как LLM выдает список, мы проводим постобработку: проверяем, не придумала ли модель несуществующую метрику, и отсекаем архивные записи.
Можно возразить, что такой многоступенчатый конвейер фильтрации кандидатов (RAG, лексический, точный) добавляет задержку (latency). Некоторые разработчики считают, что можно отказаться от промежуточных шагов и сразу использовать высокопроизводительную векторную базу данных с оптимизированным эмбеддингом, обученным на "сырых" логах, чтобы уложиться в 50 мс. Но, честно говоря, такой подход жертвует точностью: без предварительной очистки и лексического фильтра LLM просто утонет в шуме и "мусорных" метриках. Это увеличит стоимость инференса и, что критичнее, повысит риск галлюцинаций при формировании итогового ответа для пользователя M42.
Можно Ли Оптимизировать Промпты Автоматически?
Ручной промпт-инжиниринг — это долго и часто неоптимально. Мы решили пойти дальше и начали использовать фреймворк DSPy.
- DSPy позволяет нам обучать промпты! Вместо того чтобы часами подбирать нужные слова, мы описываем высокоуровневую задачу, задаем метрику качества (например,
top5_accuracy), и DSPy сам проводит оптимизацию, используя градиентные методы.
- Процесс с DSPy:
1. Определяем сигнатуру модуля (что входит и что выходит).
2. Запускаем оптимизатор (MIPROv2) на тренировочном наборе.
3. DSPy перебирает варианты промптов и находит лучший, который максимизирует нашу метрику.
> Попробуй сам: Даже простой пример показал нам прирост качества поиска на 12% после автоматической оптимизации! Это доказывает, что ИИ может настроить себя лучше, чем мы вручную.
Какую LLM Выбрать для Поиска и Построения Графиков?
Выбор модели критичен. Мы протестировали несколько LLM (OpenAI, DeepSeek, Anthropic) на 570 запросах.
- Главный вывод: Не существует одной лучшей модели для всего.
- Для структурированного вывода (построение графиков с JSON-схемой): Модели GPT (например,
gpt-4.1) показали лучшее понимание строгих схем. - Для поиска метрик (где важна релевантность): Модели вроде
qwen3-480bилиdeepseek-V3давали хорошие результаты поtop5 search accuracyпри меньшей стоимости.
Как мы Оценивали Качество Работы Ассистента?
Мы использовали два проверенных метода, чтобы убедиться, что ассистент не просто "говорит красиво", а работает точно:
- 1. Бенчмарк (Золотой набор):
Мы вручную разметили 225 запросов на графики и 570 — на поиск метрик.
- Точность: По отдельным полям (категории, платформы) точность достигает 0.95.
- Сложность: Самые большие проблемы возникли с разрезами, которые отличаются всего парой букв (например, "логическая категория" vs "категория").
- 2. Сбор Обратной Связи от Пользователей:
После запуска мы собирали лайки/дизлайки. За 2 месяца — 550 реакций, соотношение 2:1 в пользу лайков! Это мотивирует! Основная причина дизлайков — пока не все 16 000+ разрезов поддерживаются ассистентом.
Какие Результаты Внедрения m42copilot Мы Получили?
У меня для тебя хорошие новости: результат не заставил себя ждать!
За первые два месяца работы мы зафиксировали:
- Скорость построения графиков: Ускорение на 50%. Время от запроса до визуализации сократилось вдвое по сравнению с ручным методом.
- Экономия времени на поиске: Один из наших аналитиков нашел данные, которые искал месяцами, за один запрос. Это фантастика!
- Рост проникновения M42: Наблюдается рост использования инструмента на 1.5% — пришли новые пользователи благодаря простоте ИИ-интерфейса.
Какие Планы Развития ИИ-Ассистента на Будущее?
Мы только в начале пути. Наша цель — сделать ассистента еще умнее и полезнее.
В ближайших планах:
1. Расширение контекста: Нужно увеличить поддержку разрезов и довести точность их определения.
2. Диалоговый режим: Чтобы пользователи могли вести связный диалог: "А теперь покажи это же, но за прошлый месяц".
3. Интерпретация: Научить ассистента не только строить графики, но и объяснять, что они значат.
- --
Хочешь так же быстро ускорить работу твоей команды с аналитикой и освоить мощь LLM и RAG? Мы, команда Trisigma, готовы помочь тебе внедрить подобные решения. Свяжитесь с нами, чтобы обсудить, как адаптировать ИИ-ассистента под твои уникальные 16 000+ метрик! У тебя получится!