Документирование GraphQL API: Пошаговый Гайд по Schema и Playground
Что такое GraphQL API и чем он отличается от REST?
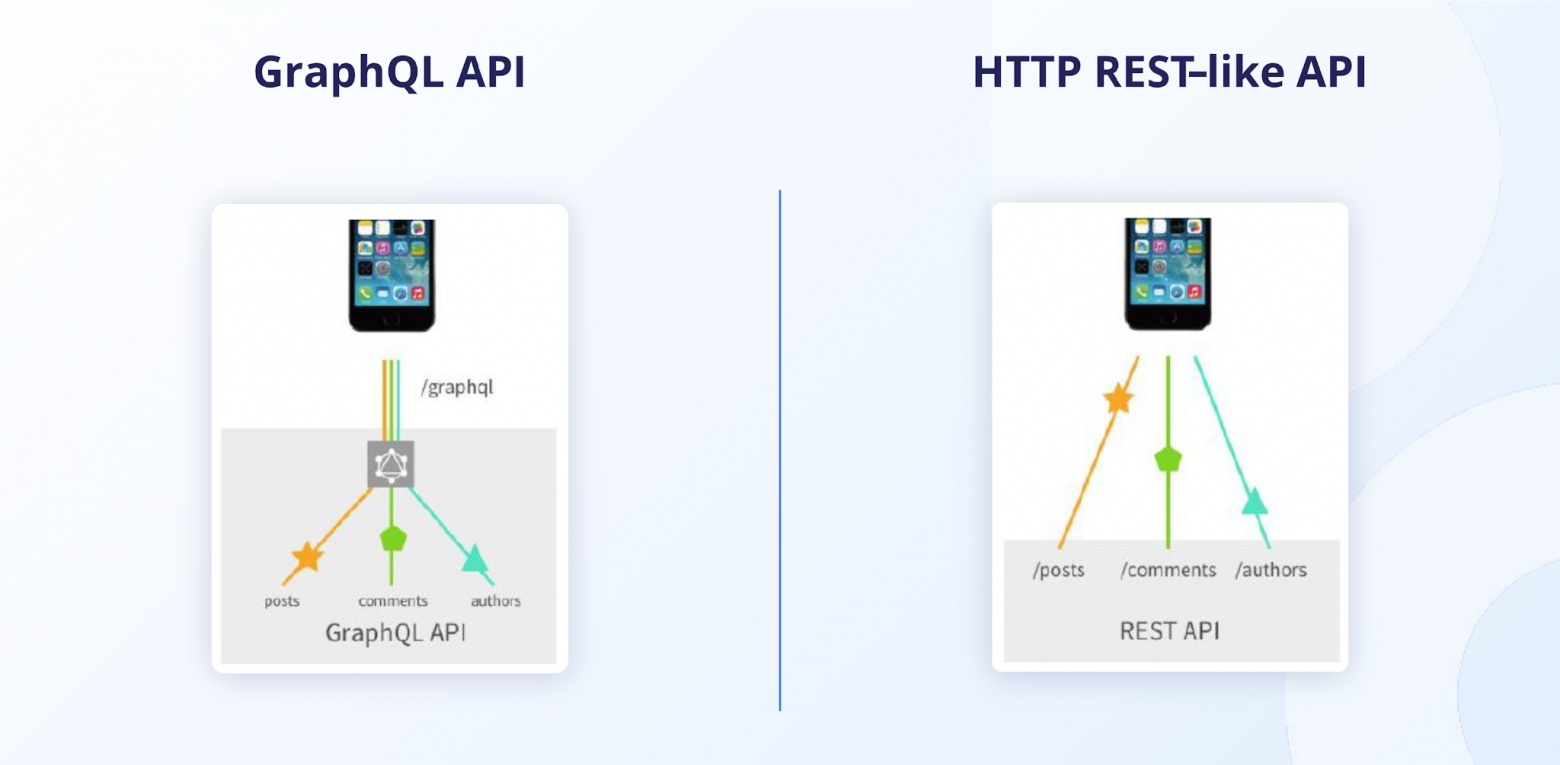
Начнем с основ: чтобы грамотно документировать GraphQL API, нужно четко понимать, как он «дышит» по сравнению с классическим REST. По сути, GraphQL даёт клиенту суперсилу: запрашивать только нужные тебе поля через один-единственный эндпоинт. REST же часто грешит тем, что вываливает весь объект целиком, даже если тебе нужна пара строчек.
Представь, что ты заказываешь пиццу. В REST ты говоришь: "Дайте мне "Пепперони"", и получаешь всё: тесто, соус, сыр, пепперони, бортики с сыром и, конечно, коробку. 📦 А в GraphQL ты заявляешь: "Мне нужно только тесто, соус и пепперони". Ты получаешь меньше данных, экономишь трафик, и не нужно потом выбрасывать лишнее. Удобно же?
Вот где GraphQL ощутимо обходит REST:
1. Объём данных: GraphQL решает проблему over-fetching (слишком много данных). Ты явно указываешь, что тебе нужно в запросе.
2. Количество эндпоинтов: В GraphQL все операции (чтение, запись, изменение) идут на один POST-эндпоинт. В REST для каждой операции нужен свой URL.
3. Связанные данные: Хочешь получить пользователя и сразу 10 его свежих постов? GraphQL сделает это одним запросом. В REST пришлось бы делать 11 отдельных обращений к серверу.

Кстати, то, как ты назовёшь операции (например, getUser, deletePost) — это не просто прихоть. Грамотный нейминг напрямую влияет на то, насколько легко читать твою документацию.
Конечно, есть мнение, что такая гибкость GraphQL усложняет кеширование на клиенте, ведь каждый запрос уникален, и стандартные HTTP-кеши не работают. Это отчасти правда. Но современные инструменты вроде Apollo Client или Relay используют нормализацию данных по ID объектов в локальном хранилище. Честно говоря, это часто даёт более гранулярное и эффективное кеширование, чем работа с огромными, статичными REST-ответами.
GraphQL Schema: Ваш Главный Источник Правды
Любая работа над API на GraphQL начинается с определения GraphQL Schema. Это твой контракт, который описывает всю структуру данных и доступные действия. Технический писатель должен иметь этот файл схемы как отправную точку.
Схема чётко прописывает:
- Типы данных (
types): Как выглядят объекты, например,UserилиBook. - Запросы (
queries): Это аналог GET-запросов (получение данных). - Мутации (
mutations): Аналог POST/PUT/DELETE (всё, что меняет состояние сервера). - Подписки (
subscriptions): Обновления в реальном времени (обычно через WebSockets).
Что нужно знать о типах в Schema?
Типы говорят нам, какие данные мы получим в ответ.
- Объектные типы: Описывают сущности. Внутри них — поля, которые могут быть скалярными (вроде
String,Int) или другими объектными типами. - Скалярные типы: Базовые кирпичики (ID, String, Boolean).
- Enums (Перечисления): Ограниченный набор значений. Например,
enum Status { ACTIVE, ARCHIVED }.
Вот как выглядит описание типа User в схеме:
type User {
id: ID!
name: String!
email: String!
posts: [Post!]! # Список постов, не может быть null
}
Как описываются операции?
Запросы (Query) — это то, что пользователи будут использовать для чтения данных:
type Query {
getAuthors: [Author!]!
getBookById (bookId: ID!): Book
}А мутации (Mutation) — это действия, которые меняют сервер. Они часто требуют входных данных через Input:
type Mutation {
createBook (bookInput:CreateBookInput!): Book!
deleteBook(bookId:ID!): Book!
}
Запомни: схема — это фундамент. Если она продумана, документация получится чёткой и надёжной.
Честно говоря, я недавно столкнулся с проектом, где фронтенд всё ещё работал на старом REST, а бэкенд только переехал на Apollo Server с Python (Django). Первые две недели мы вручную писали документацию в Swagger. И только когда я настоял, чтобы техписателю выдавали сгенерированный .graphql файл схемы, всё стало намного проще. Как только эта схема была у меня, автоматизация генерации документации через gqlgen (или аналог для Python) заняла всего один день! Мы сократили цикл выпуска документации с еженедельного до ежедневного. 🚀
Как сделать документацию удобной в GraphiQL Playground?
- GraphiQL Playground — это интерактивный инструмент, который показывает схему и позволяет сразу же тестировать запросы. Наша задача, как техписателей, — максимально обогатить эту визуализацию.
Чтобы документация выглядела достойно, мы используем комментарии в тройных кавычках ("""...""") прямо в GraphQL-схеме.
> По сути, эти комментарии парсятся и отображаются как описания полей и операций в Playground.
Внутри этих комментариев можно использовать разметку CommonMark (похоже на Markdown): заголовки, списки, ссылки.

Добавляем рабочие примеры кода
Самое ценное для разработчика — это готовый к копированию и запуску пример. Я настоятельно советую вставлять блоки кода прямо в эти комментарии.
- Почему это так важно? Разработчик видит не просто сухое описание, а готовый фрагмент, который можно сразу пробовать. Это реально экономит время на отладку синтаксиса.
Вот пример добавления примера мутации:
"""
Создает нового автора.
Требуется только имя.
Пример мутации:mutation CreateNewAuthor {
createAuthor(authorInput: { name: "Александр" }) {
id
name
}
}
"""
createAuthor (authorInput:CreateAuthorInput!): Author!
Я советую перед добавлением в схему прогнать такие примеры через GraphQL Formatter. И, если есть возможность, внедрите в шаблон генерации Playground подсветку синтаксиса (например, через Prism) и кнопку "Копировать". Это сразу выводит документацию на совершенно новый уровень! ⚡
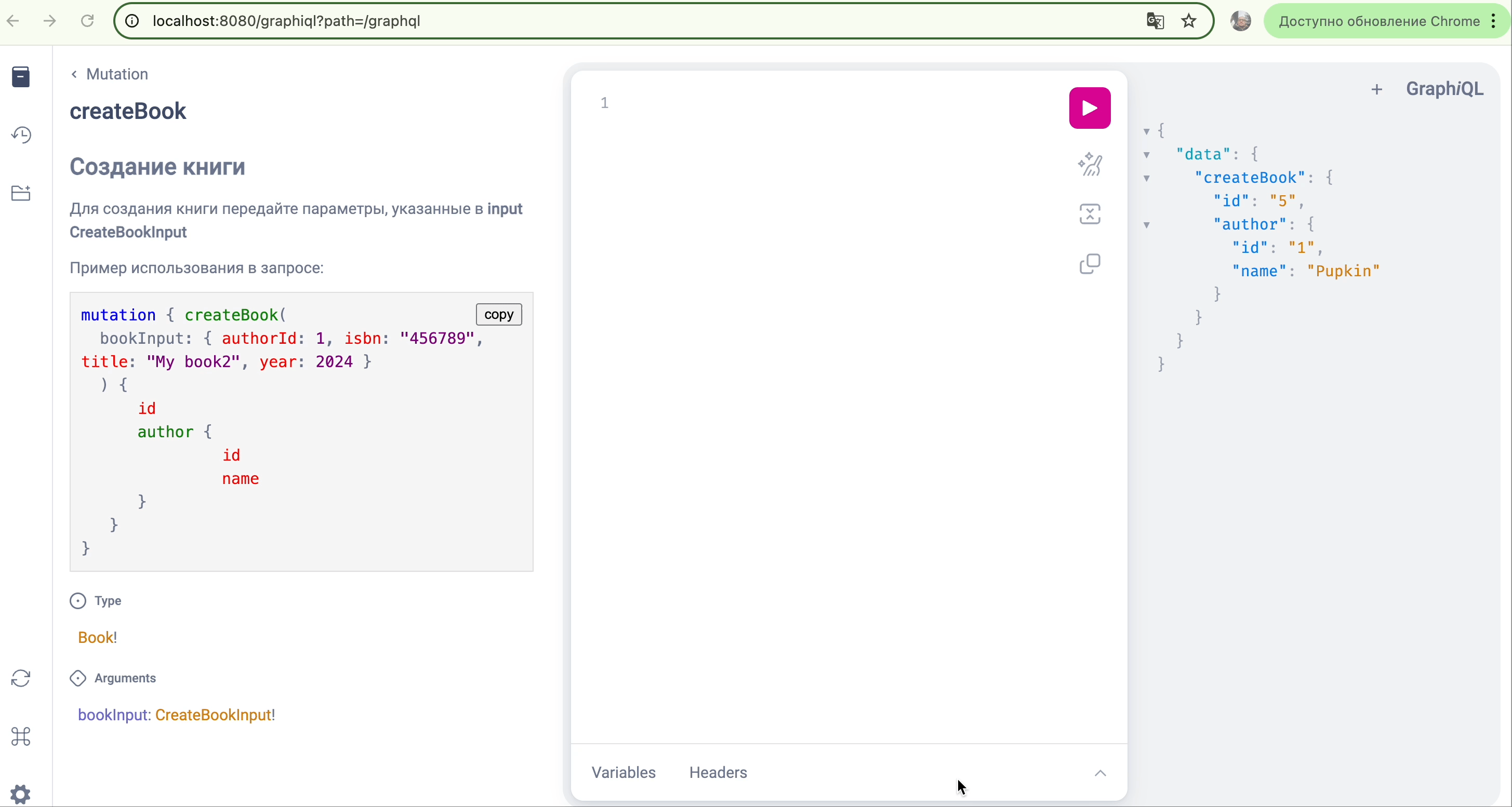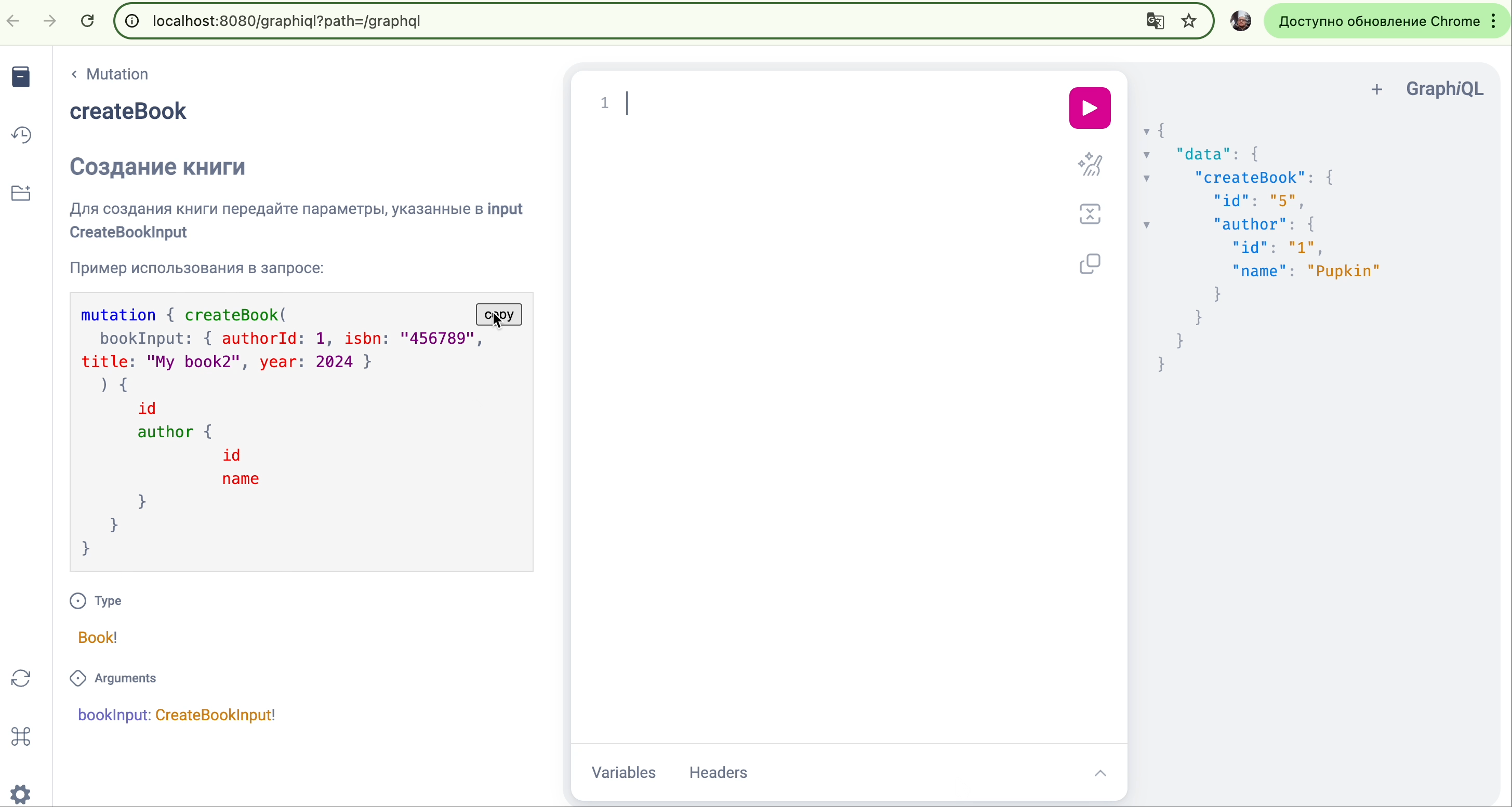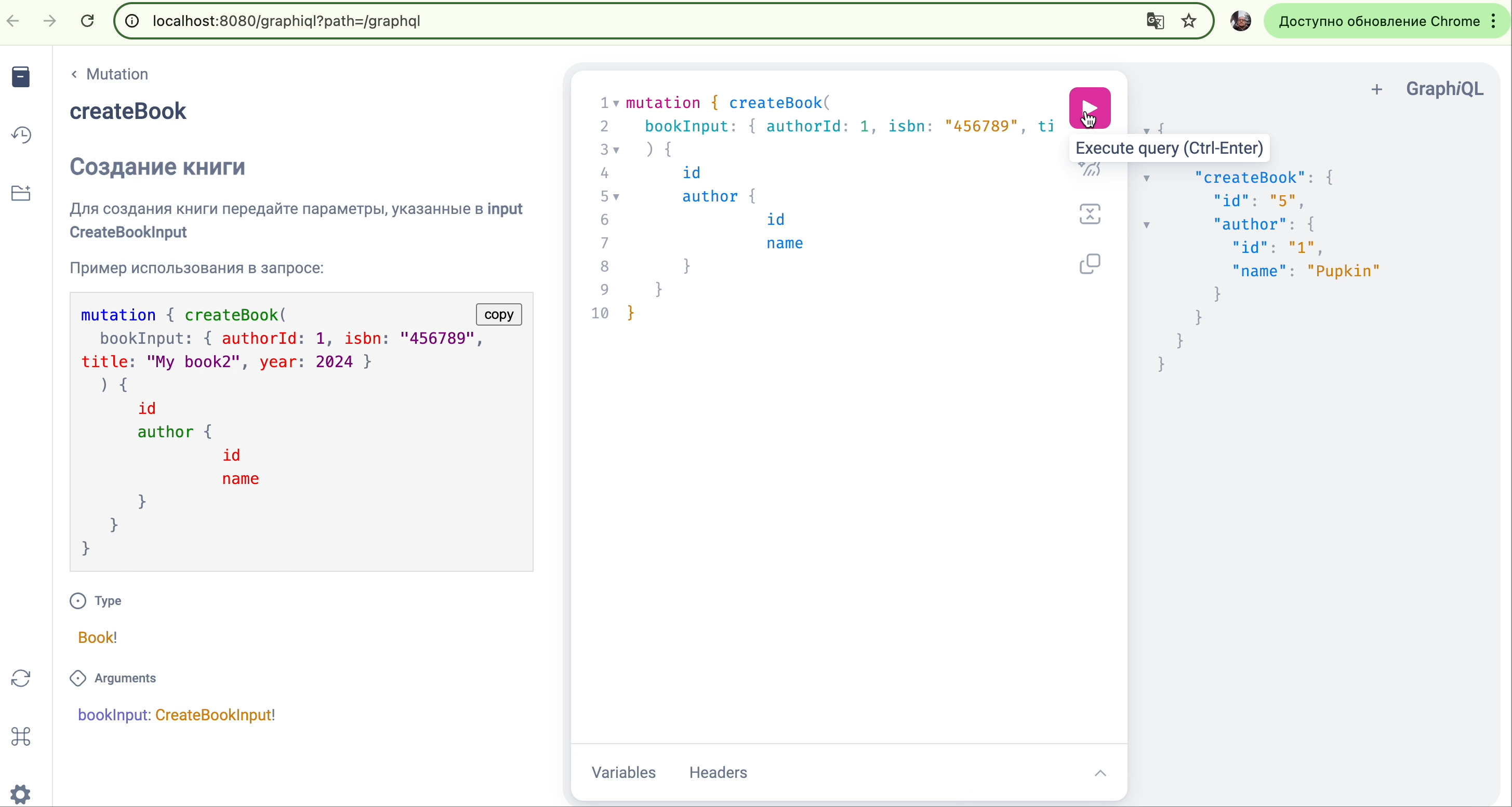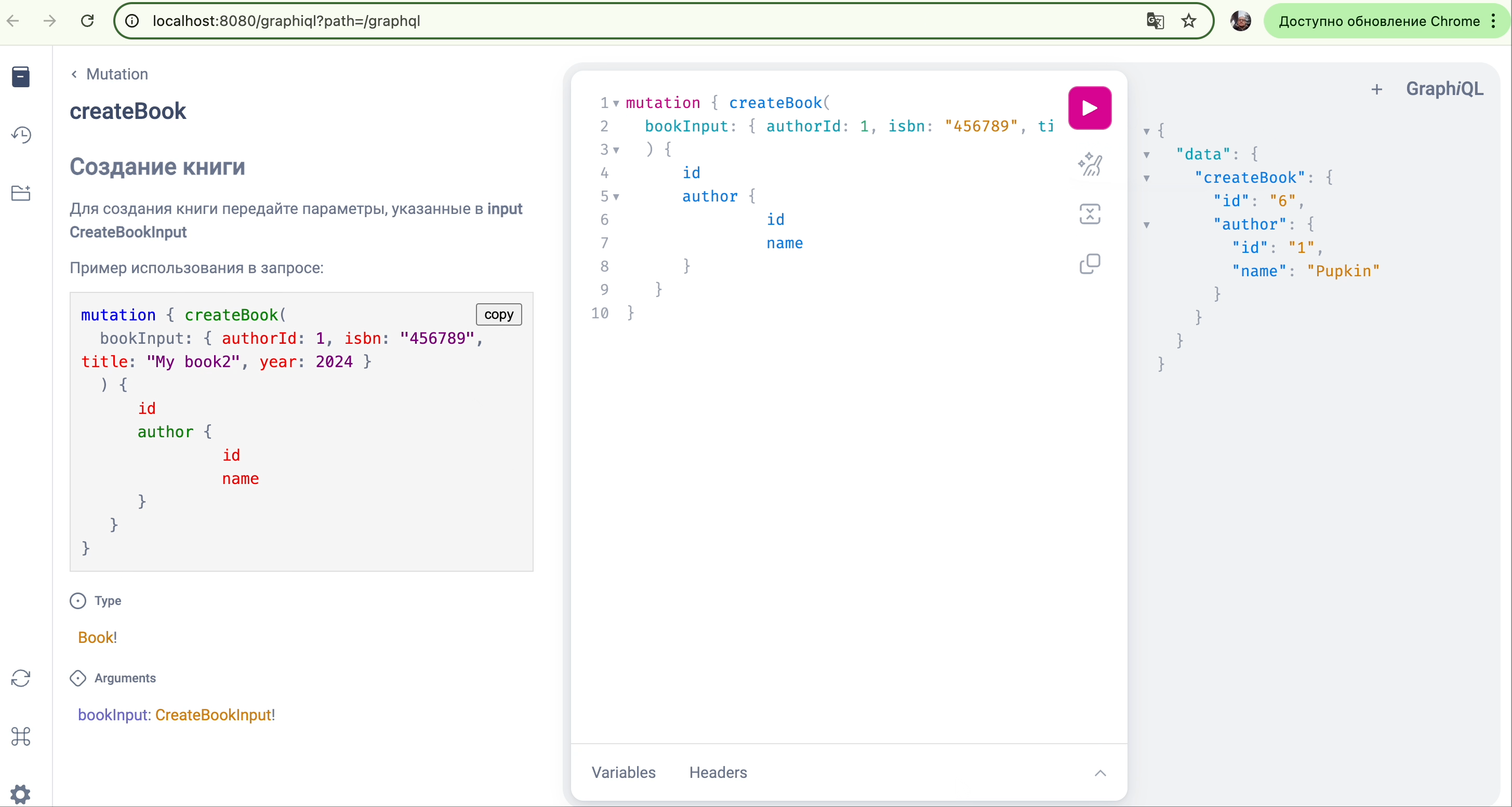
Чтобы показать, как можно программно генерировать и проверять эти описания с примерами, возьмём Python и библиотеку gql для симуляции отправки запроса.
Предположим, у нас есть строка с GraphQL-схемой, где в описании поля уже есть пример мутации (как выше). Нам нужно этот пример извлечь и проверить.
import re
# Пример строки схемы, содержащей описание с примером кода
schema_definition = """
"""
Создает нового пользователя.
Требуется только имя и email.
Пример запроса:query GetUser {
getUser(id: "usr_123") {
name
}
}
"""
create_user(name: String!, email: String!): User!
"""
schema_definition = schema_definition.strip()
# Регулярное выражение для поиска блока кода внутри тройных кавычек
# Ищем '```graphql' до следующего '```'
code_block_pattern = re.compile(r"```graphql\n(.*?)```", re.DOTALL)
# Извлекаем найденный блок
match = code_block_pattern.search(schema_definition)
if match:
example_query = match.group(1).strip()
print("--- Извлеченный пример запроса ---")
print(example_query)
# Здесь можно добавить логику для отправки этого запроса в тестовый GraphQL-эндпоинт
# Например, с использованием библиотеки requests или gql
else:
print("Пример кода не найден.")Этот скрипт использует регулярные выражения, чтобы надёжно вытащить блок кода, помеченный как ```graphql, внутри документационного комментария. Это имитирует процесс, который может использовать генератор документации для проверки валидности примеров перед их публикацией в интерактивном Playground.
Как создать статические справочники для GraphQL API?
Иногда по соображениям безопасности доступ к интерактивному Playground закрывают. В таких случаях нам нужны статические сайты-справочники. Это просто HTML-страницы с готовой документацией, которые легко раздавать.
Для создания таких сайтов используется запрос интроспекции (Introspection query).
- Что это такое? Интроспекция — это специальный GraphQL-запрос, который возвращает всю информацию о схеме API в виде JSON-ответа. Если в схеме были твои комментарии в
"""...""", они обязательно попадут и сюда!

Один из популярных инструментов для визуализации этого JSON — SpectaQL. Он берёт результат интроспекции и генерирует красивый статический сайт.
Ты можешь автоматизировать этот процесс (генератор сам делает запрос) или пойти вручную: сделать запрос интроспекции, получить JSON, скормить его SpectaQL и собрать сайт. Поскольку это Open Source, ты волен кастомизировать стили и шаблоны под брендбук компании.
Что ещё нужно документировать, кроме схемы?
Playground и статический сайт — это отличная база, но для полного понимания пользователям не хватает контекста. Я, как практик, всегда добавляю в основной портал документации следующие разделы:
1. Краткий обзор технологии: Объясни, что такое GraphQL и почему вы его используете. Аналогия с REST очень помогает новичкам быстрее въехать в концепцию.
2. Принципы построения запросов: Не просто перечисляй поля, а показывай реальные кейсы от команды разработки.
3. Описание ключевых концепций GraphQL: Это то, что выделяет GraphQL среди прочих систем.
Важные концепции GraphQL для техписателя
Обязательно опиши эти "фишки", чтобы пользователи могли писать максимально эффективные запросы:
- Псевдонимы (
aliases): Как переименовать поля в ответе, чтобы избежать конфликтов, если ты запрашиваешь одну и ту же сущность несколько раз. - Фрагменты (
fragments): Как выносить повторяющиеся наборы полей в переиспользуемые блоки. Запросы сразу становятся чище. - Переменные (
variables): Как выносить динамические значения за пределы строки самого запроса. Это критически важно для фронтенд-разработки. - Директивы (
directives): Как изменять запрос "на лету" (например, включать поле только при выполнении условия@include(if:** $condition)).
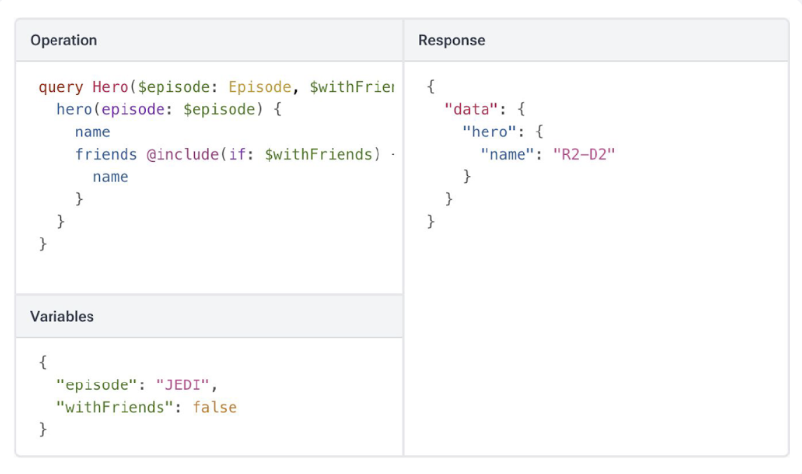
Включение этих подробностей с наглядными примерами гарантирует, что пользователи будут использовать API максимально эффективно.
Где потренироваться в документировании GraphQL API?
Чтобы прокачать навыки, нужно практиковаться на живых примерах. Начать стоит с официальных ресурсов, например, Rick and Morty API (там только Query) или GitHub API.
Но для полноценной тренировки, где можно безопасно экспериментировать с мутациями и схемой, я предлагаю локальный репозиторий.
Я собрал специальный репозиторий на GitHub. Там лежит готовая, но пока "сырая" GraphQL API. Ты можешь скачать её, развернуть локально и попрактиковаться: добавить комментарии """...""", вставить примеры кода и отформатировать схему. В нём есть подробная инструкция.
Попробуй сам! Скачай проект, внедряй все советы по комментариям и посмотри, как преображается документация в Playground.
- --
Нужна помощь с автоматизацией?
Самостоятельное внедрение интерактивных штук вроде подсветки синтаксиса или настройка генерации статических сайтов по интроспекции может занять много времени и потребовать глубокого понимания интеграции фронтенда и бэкенда.
Меня зовут Александр, я Python-разработчик, специализируюсь на автоматизации бизнеса. Моя команда и я помогаем во внедрении сложных API-решений и инструментов документирования. Мы можем помочь:
- Настроить автоматическую генерацию документации прямо из GraphQL Schema.
- Интегрировать Prism или аналогичные библиотеки для подсветки синтаксиса в GraphiQL.
- Разработать скрипты для парсинга интроспекции и сборки кастомных статических справочников.
- Обсудим ваш проект: skypoyinvest.ru