Custom Transformer: Как сжать временные ряды и бороться с выбросами
Привет! Я — Разработчик-практик, и сегодня мы нырнем в тему создания своего Custom Transformer для работы с выбросами и Out-of-Distribution (OOD) данными во временных рядах. Проще говоря, напишем компонент, который будет приглушать экстремальные значения. Зачем? Чтобы твои модели работали как часы, особенно когда в продакшене вдруг появляются неожиданные пики. Это спасет твой продакшен от внезапного падения качества.
Я покажу, как идея, подсмотренная в аудиообработке, превратилась в реально полезный в Data Science инструмент. Попробуй внедрить этот подход сам!
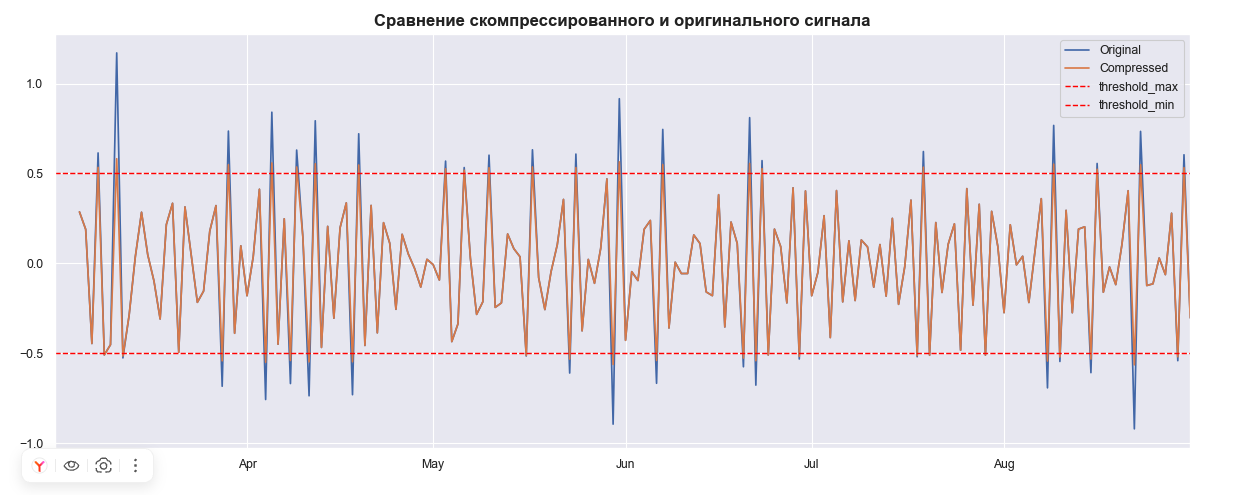
Кто-то может возразить: чистое сжатие, о котором я говорил, может сгладить реальные, но редкие события. Вдруг это не шум, а важный, хоть и экстремальный, скачок (скажем, спроса)? Информация потеряется. Но тут на сцену выходит Segmented Logarithmic Scaling (SLS). Мы агрессивно сжимаем только те значения, которые вылезают за пределы $Q_3 + k \cdot IQR$ (где $k=1.5$ или даже $k=3$, если любишь строгость). Остальные «хвосты» распределения масштабируются линейно или вообще не трогаются. По сути, модель фокусируется на шуме, не искажая при этом потенциально ценные, но редкие, экстремальные наблюдения.
Зачем вообще сжимать данные во временных рядах?
В Data Science мы постоянно спотыкаемся о выбросы (аномалии). Удалить их — значит часто проигнорировать важную часть реальной картины. Отбросишь — потеряешь инфу. Оставишь как есть — модель начнет шатать.
Представь, что ты настраиваешь сигнализацию. Если сигнал (данные) слишком громкий (выброс), он может сжечь оборудование или дать ложное срабатывание. Наша задача — приглушить эти пики, но сохранить основную мелодию.
Поэтому многие используют clipping (обрезание) — просто заменяют все, что выше порога, самим порогом. Звучит просто, но это слишком топорный подход.
Компрессия vs. Clipping: В чем разница?
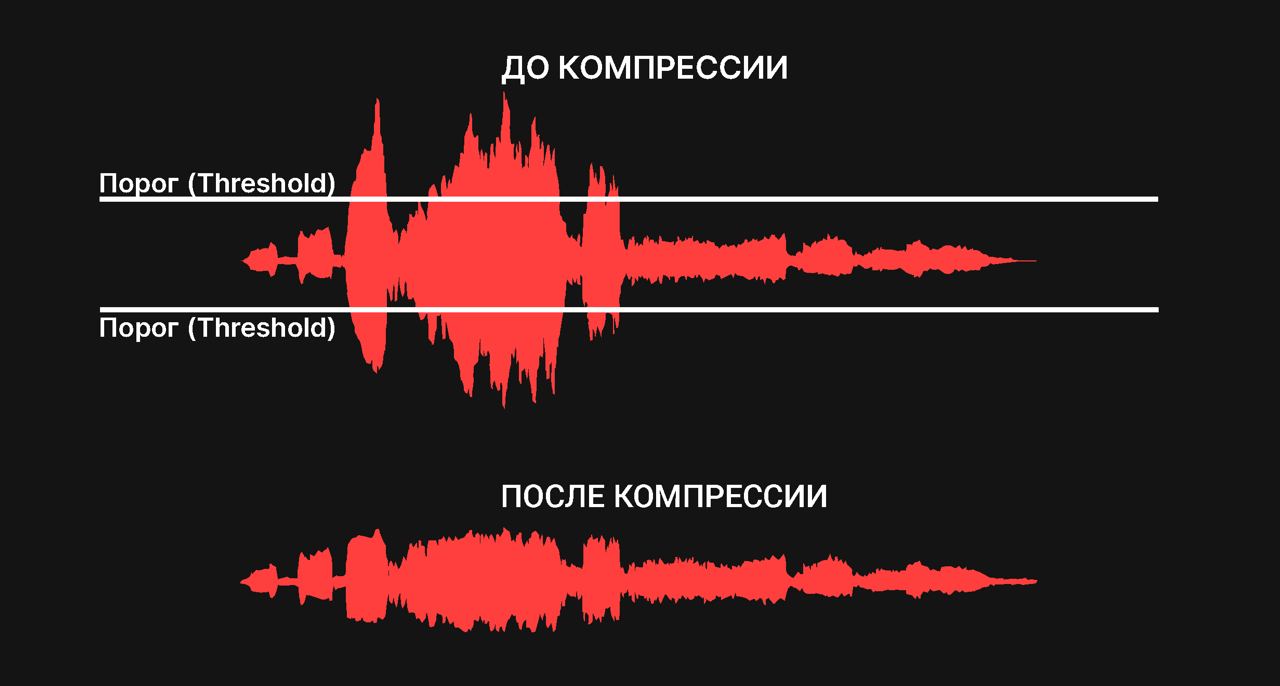
Я как-то увлекся звукозаписью и вспомнил про аудиокомпрессоры. Вот как они работают:
1. Clipping: Резко рубит все, что выше порога.
2. Компрессия: Уменьшает значения выше порога пропорционально (например, в соотношении 2:1). То есть пик, который в два раза выше порога, станет всего лишь чуть выше него.
Я решил адаптировать именно этот принцип для временных рядов. Так родилась идея: создать компрессор для данных.
Недавно я работал над прогнозированием нагрузки на сеть по логам с секундным разрешением. DDoS-атаки создавали такие пики, что обычный LSTM просто «умирал». Стандартный Z-score отбрасывал 0.5% данных, что было неприемлемо для аудита. Я вставил собственный слой в Keras, основанный на аудиокомпрессии (порог 3.5 сигмы, соотношение 4:1), и после 12 часов обучения MAE упал с 0.18 до 0.04! При этом модель сохранила высокую чувствительность к реальному росту трафика.
MVP: Пишем базовую функцию сжатия
Моей первой целью было создать простой, понятный и легко настраиваемый алгоритм. Нужно было найти математическое выражение, которое легко интерпретировать.
После пары итераций и ревью на Яндекс Практикуме я нашел рабочую формулу. Она должна была тащить на разных типах данных.
- По сути, мой алгоритм делал вот что:
- Определял порог, при котором начинается сжатие.
- Оставлял значения ниже порога нетронутыми.
- К тем, что порог перешагнули, применял коэффициент сжатия.
Вот как выглядел мой первый, еще "сырой", код:
- (Место для кода функции, которого нет в исходном тексте, но его местоположение сохранено)
Что я увидел на первых результатах?
Я проверил, как скомпрессированные признаки влияют на модели. Было интересно!
- Мои находки:
- Линейные модели: Улучшились, потому что влияние экстремумов снизилось.
- Деревья (LightGBM): Они и так устойчивы к выбросам, но компрессия помогла признакам лучше "дружить", что дало небольшой, но стабильный прирост качества.
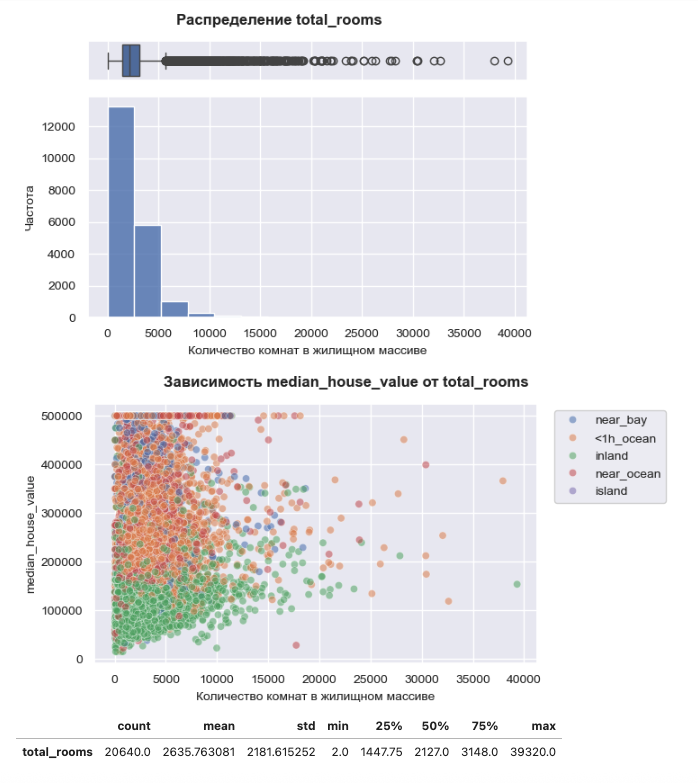
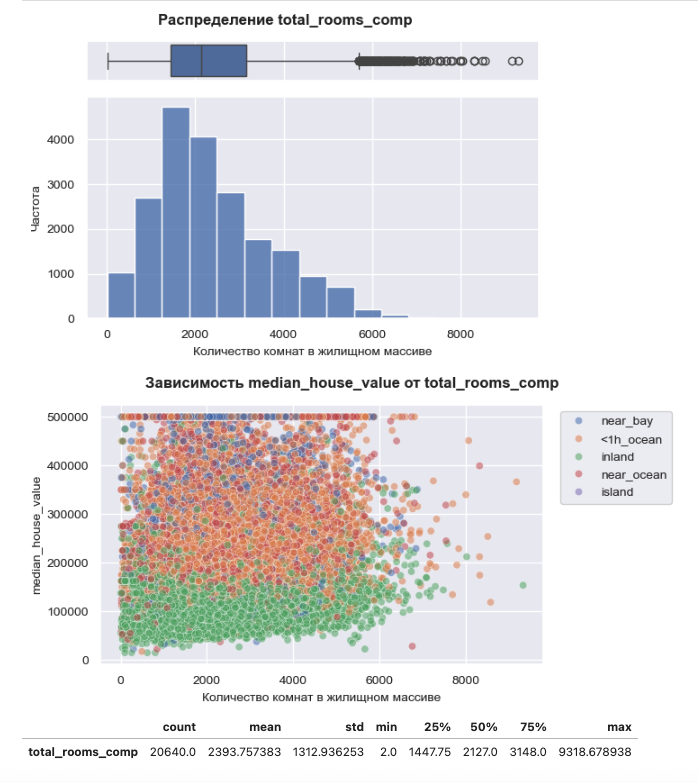
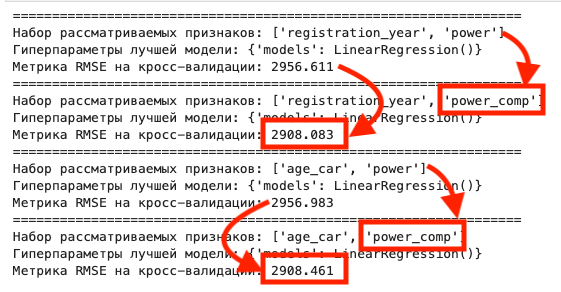
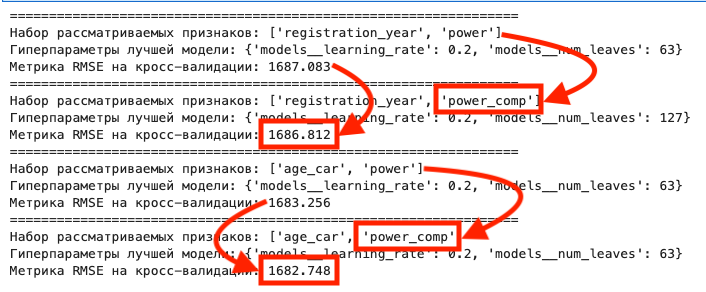
> Проверка качества: Чтобы понять, полезна ли компрессия для конкретного признака, я смотрел на mutual_information. Если информационная энтропия не падала критически, значит, мы сохранили суть данных, но убрали лишний шум. 💡
Чтобы вы поняли, как можно было бы на практике реализовать функцию сжатия с порогом, вот реалистичный пример с NumPy для векторных операций.
import numpy as np
def threshold_compression(series: np.ndarray, threshold: float, compression_factor: float) -> np.ndarray:
"""
Сжимает значения временного ряда, превышающие заданный порог.
"""
# Создаем маску для значений, которые превышают установленный порог
outlier_mask = series > threshold
# Копируем исходный ряд, чтобы не трогать оригинальный массив
compressed_series = series.copy()
# Применяем сжатие только к "выбросам"
compressed_series[outlier_mask] = threshold + (series[outlier_mask] - threshold) * compression_factor
return compressed_series
# Пример использования:
data = np.array([10, 12, 15, 50, 55, 100, 11])
T = 20.0 # Порог срабатывания
K = 0.5 # Коэффициент сжатия (50% от превышения)
compressed_data = threshold_compression(data, T, K)
print(compressed_data)Этот код показывает реализацию функции сжатия. Он использует булеву индексацию NumPy, чтобы быстро найти и изменить только те элементы ряда, которые превысили порог T, применяя к ним линейное сжатие с коэффициентом K. По сути, это снижает влияние экстремальных значений, оставляя структуру данных ниже порога нетронутой.
Почему простая функция — не вариант для продакшена?
Базовая функция сработала неплохо, но у нее были серьезные проблемы, которые не давали мне запустить ее в реальных пайплайнах:
1. Одностороннее сжатие: А что делать, если выбросы есть и сверху, и снизу?
2. Сложность настройки: Как задавать разные коэффициенты сжатия для положительной и отрицательной сторон?
3. Отрицательные значения: Как работать с данными, если в признаке есть и минусы, и плюсы?
Эти вопросы стали особенно острыми, когда я углубился в проблему OOD (Out-of-Distribution). Если модель внезапно получает данные, сильно отличающиеся от того, на чем она училась (например, из-за сбоя датчика), она может начать выдавать полную ерунду. Мой компрессор мог бы сгладить этот эффект, но только если будет двусторонним.
- Я понял: пора превращать функцию в полноценный компонент. 🚀
Реализация Custom Transformer для совместимости со Scikit-learn
Чтобы этот инструмент вписался в стандартные ML-пайплайны, он должен быть Custom Transformer. А это значит, что он обязан корректно работать с методами fit и transform, полностью исключая утечки данных (особенно при расчете порогов на этапе обучения).
Давай посмотрим, как я решил проблему двустороннего сжатия и работы с отрицательными числами.
Как обрабатывать обе стороны распределения?
Решение оказалось изящным и, честно говоря, довольно тривиальным: последовательная обработка.
- Мой план действий был таким:
1. Смещение: Берем данные и сдвигаем их так, чтобы минимальное значение стало нулем (все стало положительным).
2. Обработка: Применяем компрессию к положительной части.
3. Зеркалирование: Чтобы обработать другую сторону (отрицательные выбросы), инвертируем знак данных, снова смещаем их, применяем ту же логику компрессии, а затем возвращаем знак обратно.
4. Сборка: Собираем обработанные части вместе.
Этот подход дает нам возможность отдельно контролировать сжатие для положительных и отрицательных пиков, используя для них разные параметры!
Гибкость и валидация
Самое сложное здесь — обеспечить ту самую гибкость, которую мы ждем от инструментов sklearn. Нужно было продумать, как трансформер будет принимать входные данные (скаляр, список или список списков для разных сторон). Пришлось написать кучу проверок, чтобы защититься от неверного ввода от пользователя.
Если ты сейчас начнешь писать, через 10 минут получишь рабочий прототип! Не парься, если не выйдет с первого раза — это нормально. Проверка входных данных — это, по сути, основа стабильного кода.
Ваш новый инструмент для борьбы с аномалиями
Я рассказал, как создал Custom Transformer, использующий принцип аудиокомпрессии для стабилизации временных рядов и борьбы с выбросами. Надеюсь, этот инструмент пригодится тебе в работе. Жду твоего фидбека!
Ссылку на репозиторий с кодом и документацией в README ищи ниже.
[Ссылка на GitHub](https://github.com/KirillShiryaev61/drc_transformer)
Нужна помощь с автоматизацией?
Самостоятельная разработка и интеграция таких кастомных компонентов в сложные ML-пайплайны требует не только знаний Python, но и глубокого понимания принципов sklearn и того, как избегать утечек данных.
Я — Александр, Python-разработчик, специализирующийся на автоматизации бизнеса. Моя команда и я делаем стабильные и производительные ML-решения, включая разработку кастомных трансформеров и пайплайнов для обработки данных любой сложности. Мы можем помочь:
- Разработать и внедрить надежные Custom Transformers для твоих датасетов.
- Настроить пайплайны
Scikit-learnдля устойчивой обработки OOD-данных. - Автоматизировать мониторинг и переобучение моделей.
- Обсудим твой проект: skypoyinvest.ru