AB-Тесты: Почему "Подглядывание" Искажает Результаты?
Частая ловушка при проведении AB-тестов — это постоянный пересчет p-value по мере накопления данных. Мы досрочно принимаем решение, как только видим $p < 0.05$. Если ты делаешь это без специальной процедуры, доля ложных срабатываний (ошибка первого рода) взлетает до небес. Честно говоря, это происходит потому, что каждая новая проверка — это дополнительный шанс поймать случайное колебание данных и принять его за реальный эффект.
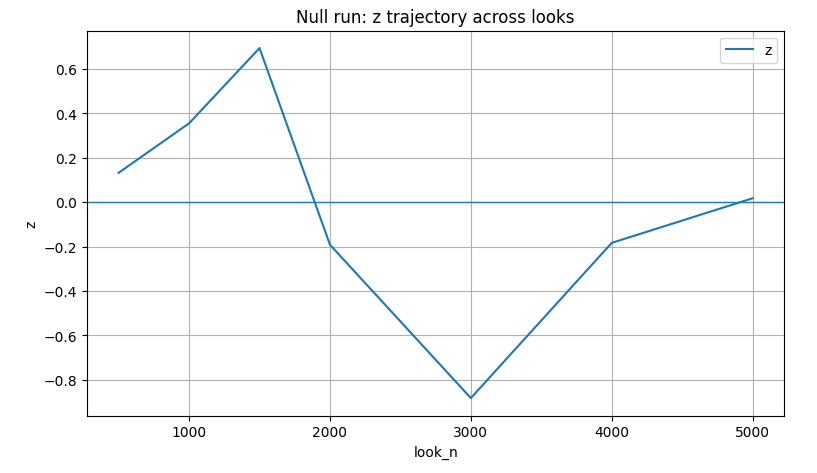
Бизнес требует скорости. Руководителям нужно знать, не "сливает" ли вариант B, а команде хочется поскорее зафиксировать победу. Естественное желание проверить цифры каждый день ведет к статистическому бардаку.
Есть мнение, что игнорировать промежуточные результаты совсем непрактично. Особенно, когда речь идет о долгих A/B тестах, где влияние на ключевые метрики может быть очень важным. Некоторые команды пытаются использовать поправочные коэффициенты, вроде поправки Бонферрони, для каждой точки наблюдения, чтобы держать под контролем общий уровень ошибки I рода. Но, хотя эти методы и позволяют иногда заглянуть в данные, они часто требуют либо намного большего размера выборки, либо большего времени на тест, чтобы достичь той же мощности, что и заранее спланированный последовательный дизайн. По сути, это замедляет принятие решений.
Что Такое Ошибка Первого Рода и Как Она Растет при Мониторинге?
Уровень значимости $\alpha$ (обычно 0.05) показывает, какова вероятность ошибочно отклонить нулевую гипотезу. Проще говоря, это шанс заявить об эффекте, которого на самом деле нет. При стандартном фиксированном тесте мы делаем это один раз, в самом конце.
Но когда мы начинаем подглядывать снова и снова, мы, по сути, повторяем попытку увидеть что-то редкое. Даже если истинного эффекта нет ($\mu_T = \mu_C$), шум иногда сам по себе генерирует низкое p-значение. Если разрешить тесту завершиться при первом таком событии, вероятность ошибки экспоненциально растет с числом проверок $K$.
Формула ниже помогает понять масштаб проблемы (хотя в реальности проверки зависимы друг от друга):

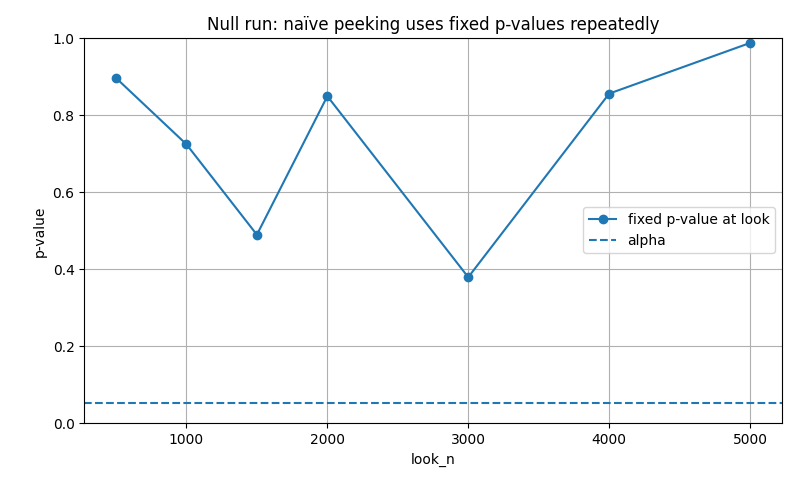
В реальном AB-тесте проверки связаны, ведь мы считаем на одних и тех же накопленных данных. Но принцип один: чем чаще мы смотрим, тем выше шанс поймать случайное "значимое" событие.
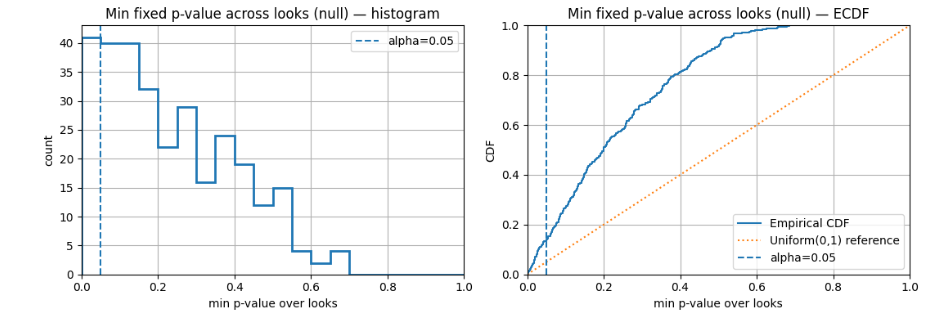
Недавно я видел, как команда аналитиков, торопясь, остановила A/B тест нашего нового скорингового алгоритма (Python/Pandas). CTR показал рост в 8% уже на третий день, и они тут же применили стандартный $p < 0.05$. Мы настояли на продолжении до запланированных 14 дней. По итогу, весь этот прирост оказался статистически незначимым ($p$-value вырос до 0.18). Чистая случайность, вызванная колебаниями трафика в начале недели. Это наглядно показало: пара преждевременных "заглядываний" может угробить надежность всего эксперимента.
Как Исправить Ситуацию: Введение Последовательного Тестирования
Многократные проверки — это головная боль, которую решает групповое последовательное тестирование (Group Sequential Testing). Это оптимальный способ мониторинга, который держит общий уровень ошибки первого рода на заданной отметке $\alpha$.
Как это работает:
1. Планируем точки: Заранее определяем, когда именно мы будем смотреть данные (например, на 25%, 50%, 75% и 100% от планируемого объема).
2. Уникальные пороги: Каждая точка анализа получает свой, уникальный порог для принятия решения.
3. Контроль ошибки: Эти пороги настраиваются так, чтобы общий шанс получить ложноположительный результат по всей процедуре не превышал $\alpha$.
Это золотая середина между полным игнорированием мониторинга и постоянной слежкой с риском завысить ошибку.
Пример из жизни: Команда SaaS-продукта запускала дорогой A/B тест новой воронки регистрации. Нужно было быстро принимать решение о масштабировании, так как поддержка двух параллельных сред "съедала" бюджет. Решение: вместо ожидания полных 30 дней мы применили последовательное тестирование с тремя точками анализа (33%, 66% и 100% выборки), используя пороги O’Brien-Fleming. Результат? На отметке 66% трафика (через 20 дней) разница в конверсии между A (4.12%) и B (4.48%) стала значимой ($p < 0.01$). Мы остановили тест и внедрили вариант B на 10 дней раньше. Экономия — около 15% операционных расходов! 🚀
Как Рассчитать Z-Статистику в Контрольных Точках?
Для метрик, основанных на средних (типа ARPU или конверсии), мы оперируем разностью средних и стандартной ошибкой. Чтобы все было честно, нам нужна Z-статистика.
Оценка эффекта $\hat{\delta}$ в любой контрольной точке $j$:

:

Стандартная ошибка $\text{SE}(\hat{\delta}_j)$:

И вот наша Z-статистика $Z_j$:

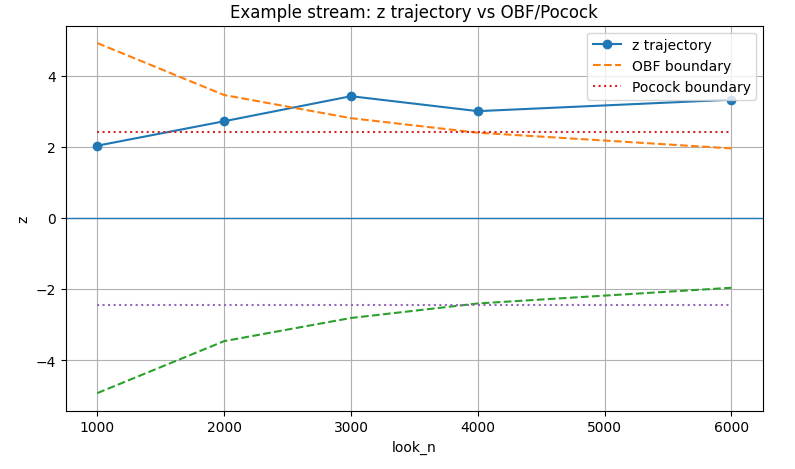
Мы сравниваем модуль $|Z_j|$ с критическим порогом $C_j$:

Если $|Z_j| > C_j$, эксперимент можно смело сворачивать досрочно.
Как Выбирать Частоту Проверок и Контрольные Точки?
Не надо превращать мониторинг в постоянную реакцию на каждую микро-флуктуацию. Частоту проверок лучше привязать к объему собранных данных, а не ко времени (если трафик скачет).
Если $N$ — наш плановый объем данных в финале, то доля накопленных данных в точке $j$ — это $t_j = N_j / N$. Проверенная временем схема контрольных точек $t_j$ выглядит так:
- Начинать анализ не раньше, чем собрано 20–25% данных.
- Всего 4–7 проверок, включая финальную.
Рабочая сетка: $\{0.25, 0.50, 0.75, 1.00\}$. Это дает возможность быстро реагировать, но не дает нам принимать решения на слишком крошечных выборках.


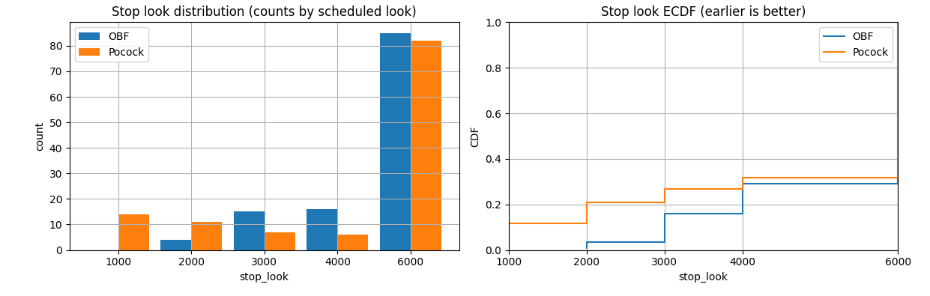
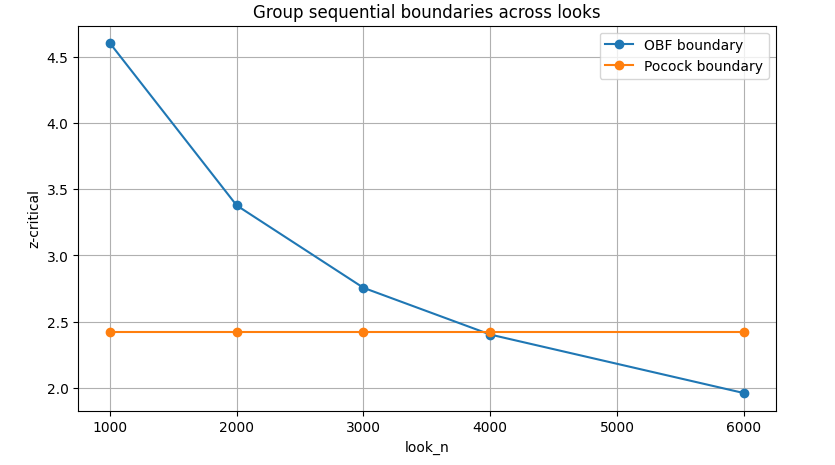
Pocock vs. OBrien-Fleming: Какие Пороги Применить?
Выбор между этими методами определяет, насколько строгими будут ваши ранние и поздние проверки. Оба подхода "распределяют" допустимую ошибку $\alpha$ между $K$ точками.
OBrien-Fleming: Осторожность в Начале
OBrien-Fleming выставляет очень жесткие ранние пороги. Это гарантирует, что досрочное завершение произойдет только при по-настоящему мощном сигнале. Постепенно, ближе к финишу, пороги "смягчаются" и становятся почти как в обычном, фиксированном тесте.
Формула для порога $C_j$ (где $z_{1-\alpha/2}$ — квантиль стандартного нормального распределения):


- Тут есть важный момент: Этот метод любят команды, которые хотят следить за тестом, но не готовы принимать решения, основанные на слабом, только что появившемся сигнале.
Pocock: Равномерная Строгость
Метод Pocock задает пороги более равномерно. Ранние пороги здесь ниже, чем у OBrien-Fleming, что может привести к большему числу досрочных остановок. Но плата за это — более строгий порог на финальной проверке.
На симуляциях при нулевом эффекте наивное подглядывание дало ошибку около 0.14. А вот Pocock удержал ошибку на уровне $\approx 0.05$, а OBrien-Fleming — на уровне $\approx 0.055$. Оба метода отлично контролируют $\alpha$. 💡
Что Нужно Зафиксировать До Старта Эксперимента?
Чтобы последовательное тестирование работало как надо, и чтобы избежать споров, протокол нужно закрепить заранее. Если пытаться подстроить правила "на ходу", ты просто потеряешь всю статистическую силу.
- Пять параметров, которые нужно решить до запуска:
1. Плановый Горизонт: Объем данных $N$ или время, нужное для достижения мощности при минимальном ожидаемом эффекте.
2. Сетка Контрольных Точек: Доли от $N$ или конкретные дни.
3. Уровень Значимости ($\alpha$): И тип теста (односторонний или двусторонний).
4. Метод Порогов: Выбираем Pocock или OBrien-Fleming.
5. Правило Завершения: Четкое условие, когда тест останавливается (например, пересечение порога $C_j$).
Внедрение этих правил гарантирует, что твой мониторинг будет не только информативным, но, что важнее, статистически надежным.
Итоги: Выбираем Правильный Подход к Мониторингу
Если ты регулярно пересчитываешь p-value обычного фиксированного теста, ты гарантированно повышаешь риск получить ложный позитив. Групповое последовательное тестирование (с O’Brien-Fleming или Pocock) — это индустриальный стандарт для корректного мониторинга.
OBrien-Fleming более консервативен, Pocock быстрее дает результат, но требует более строгого финального подтверждения.
Если самостоятельная настройка процедур, расчет порогов и валидация через симуляции кажутся слишком сложными или долгими, лучше поручить это тем, кто в этом разбирается.
- --
Нужна помощь с автоматизацией?
Настройка надежных процедур AB-тестирования, особенно с учетом динамического мониторинга, требует глубокого понимания статистики и системной интеграции. Если настроить неверно, потеряешь время и примешь ошибочные бизнес-решения.
Я — Александр, Python-разработчик по автоматизации бизнеса. Моя команда и я помогаем строить надежные эксперименты и интегрировать аналитические системы. Мы можем:
- Разработать кастомные пайплайны для последовательного тестирования на Python (используем
scipyилиstatsmodels). - Настроить автоматическое уведомление о досрочном завершении теста по правилам OBrien-Fleming.
- Интегрировать результаты тестов прямо в твои дашборды и системы отчетности.
- Обсудим твой проект: skypoyinvest.ru